Das Wichtigste in Kürze
Microsoft hat den Researcher, den Recherche‑Agenten in Microsoft 365 Copilot, grundlegend weiterentwickelt. Ziel dieser Neuerung ist es, komplexe Recherchen im Arbeitsalltag zuverlässiger, tiefer und besser überprüfbar zu machen.
Statt nur ein einziges KI‑Modell zu verwenden, setzt Microsoft jetzt auf sogenannte Multi Model Intelligence. Das bedeutet, dass mehrere unterschiedliche KI‑Modelle gemeinsam an einer Recherche arbeiten. Die neuen Funktionen heißen Critique und Council.
– Critique prüft KI‑Texte automatisch auf Vollständigkeit, Struktur und Quellen
– Council vergleicht mehrere KI‑Antworten miteinander und zeigt Unterschiede offen auf
Damit bewegt sich Microsoft einen wichtigen Schritt weg von „KI antwortet einfach“ hin zu KI denkt, prüft und erklärt nachvollziehbar.

Was ist der Microsoft 365 Copilot Researcher
Der Researcher ist ein spezieller Agent innerhalb von Microsoft 365 Copilot. Er wurde dafür entwickelt, umfangreiche und anspruchsvolle Recherchen im Unternehmenskontext zu übernehmen.
Das können zum Beispiel sein:
- Markt und Wettbewerbsanalysen
- rechtliche oder regulatorische Themen
- technische Fragestellungen
- strategische Entscheidungsgrundlagen
Der Researcher arbeitet dabei direkt im Arbeitsfluss, also innerhalb der gewohnten Microsoft‑365‑Umgebung. Ziel ist es nicht nur, schnelle Antworten zu liefern, sondern strukturierte Berichte mit Quellen zu erstellen, auf die man sich verlassen kann.

Warum ein einzelnes KI Modell oft nicht ausreicht
Viele KI Systeme arbeiten nach einem einfachen Prinzip. Ein einziges Modell übernimmt Planung, Recherche, Schreiben und Bewertung. Das ist schnell, hat aber klare Schwächen.
Typische Probleme bei diesem Ansatz sind unvollständige Analysen, übersehene Aspekte oder Aussagen, die zwar logisch klingen, aber nicht sauber belegt sind. Gerade bei wichtigen Entscheidungen kann das problematisch sein.
Microsoft verfolgt mit dem Researcher deshalb einen anderen Ansatz. Mehrere KI Modelle übernehmen unterschiedliche Rollen und kontrollieren sich gegenseitig. Dieses Zusammenspiel nennt Microsoft Multi Model Intelligence.
Einführung in Multi Model Intelligence
Multi Model Intelligence bedeutet, dass mehrere KI‑Modelle bewusst unterschiedliche Rollen übernehmen.
Statt einer einzigen „denkenden KI“ gibt es jetzt:
- Modelle, die Inhalte erstellen
- Modelle, die Inhalte prüfen
- Modelle, die unterschiedliche Antworten vergleichen
Diese Modelle stammen unter anderem aus sogenannten Frontier Labs, darunter OpenAI und Anthropic. Ziel ist es, Stärken verschiedener Modelle zu kombinieren, statt sich auf eines zu verlassen.
Critique einfach erklärt
Critique ist eine neue Multi‑Model‑Funktion im Researcher und wird automatisch verwendet, wenn im Model Picker die Option „Auto“ ausgewählt ist.
Man kann sich Critique wie ein eingebautes Vier‑Augen‑Prinzip vorstellen:
- Ein KI‑Modell übernimmt die eigentliche Recherche und erstellt einen ersten Bericht
- Ein zweites KI‑Modell liest diesen Bericht anschließend wie ein fachlicher Prüfer
Dieses prüfende Modell schreibt keinen eigenen Text, sondern verbessert gezielt den bestehenden Bericht.

Wie Critique technisch arbeitet
Critique orientiert sich an klassischen Bewertungsverfahren aus Wissenschaft und professioneller Recherche. Die Prüfung erfolgt anhand klar definierter Kriterien, sogenannter Rubrics.
Dabei konzentriert sich Critique auf drei Hauptbereiche:
Zuverlässigkeit der Quellen
Es wird überprüft, ob vertrauenswürdige, fachlich passende Quellen verwendet werden und ob diese zur Fragestellung passen.
Vollständigkeit des Berichts
Der Text wird darauf untersucht, ob die ursprüngliche Fragestellung wirklich vollständig beantwortet wurde oder ob wichtige Aspekte fehlen.
Strenge Belegpflicht
Zentrale Aussagen müssen klar auf Quellen gestützt sein. Schwach belegte oder zu vage Aussagen werden präzisiert oder abgeschwächt.
Microsoft betont, dass genau diese Gleichgewichtung von Erstellung und Bewertung zu deutlich besseren Ergebnissen führt.
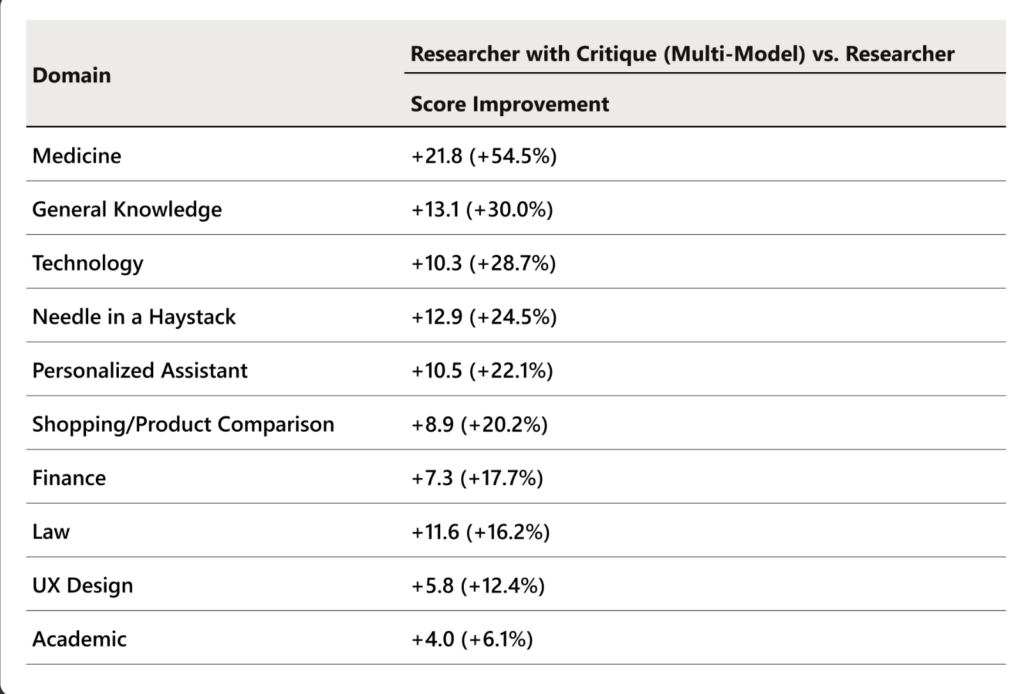
Performance‑Validierung mit dem DRACO Benchmark
Um die Wirkung von Critique objektiv zu messen, hat Microsoft den DRACO Benchmark eingesetzt. DRACO steht für:
Deep Research Accuracy, Completeness and Objectivity
Der Benchmark umfasst:
- 100 komplexe Rechercheaufgaben
- aus 10 unterschiedlichen Fachgebieten, darunter Medizin, Technologie und Recht
- reale Nutzungsszenarien aus großen Forschungssystemen
Die Bewertung erfolgte entlang von vier Dimensionen:
- faktische Genauigkeit
- Breite und Tiefe der Analyse
- Präsentationsqualität
- Qualität der Quellenangaben
Als Bewertungsinstanz diente GPT‑5.2, das in der zugrunde liegenden Studie als das strengste Bewertungsmodell bezeichnet wird. Alle Ergebnisse wurden über fünf unabhängige Durchläufe gemittelt, um Vergleichbarkeit zu gewährleisten.
Die Ergebnisse zeigen:
- die größten Verbesserungen bei Analysebreite und Tiefe
- deutliche Fortschritte bei Struktur und Verständlichkeit
- messbare Steigerung der faktischen Genauigkeit
In acht von zehn Fachbereichen schnitt Researcher mit Critique signifikant besser ab als der Single‑Model‑Ansatz.
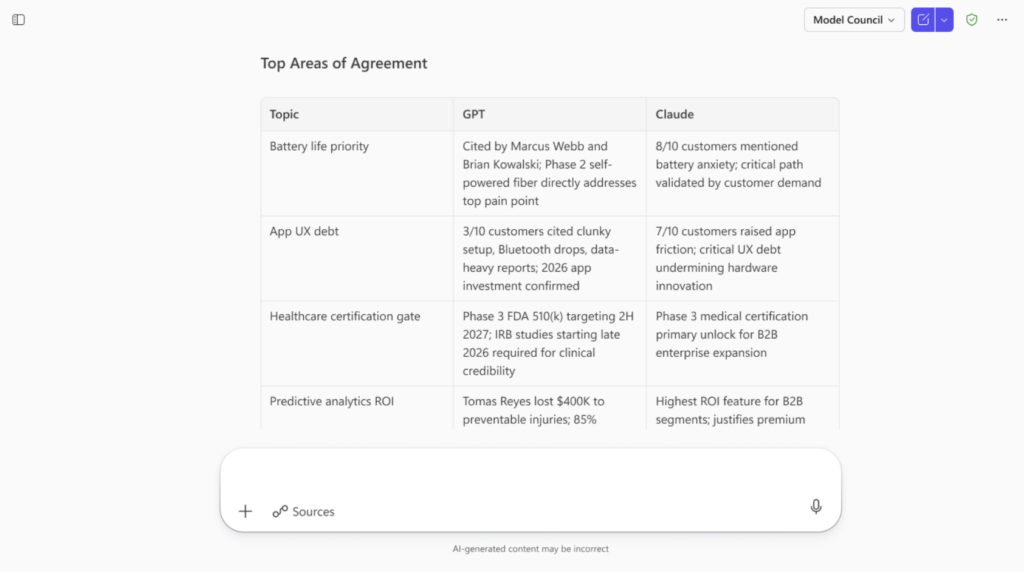
Council – mehrere KI‑Perspektiven gleichzeitig
Neben Critique stellt Microsoft mit Council einen alternativen Modus zur Verfügung.
Im Council‑Modus:
- beantworten mehrere KI‑Modelle dieselbe Fragestellung parallel
- jedes Modell erstellt einen vollständigen eigenen Bericht
- ein separates Bewertungsmodell erstellt anschließend eine Zusammenfassung
Diese Zusammenfassung zeigt:
- wo sich die Modelle einig sind
- wo sich ihre Einschätzungen unterscheiden
- welche einzigartigen Beiträge jedes Modell liefert
Council soll Anwendern helfen, unterschiedliche Perspektiven bewusst zu vergleichen, statt nur eine einzelne Antwort zu erhalten.
Was Microsoft damit konkret verbessert
Mit den neuen Funktionen Critique und Council verfolgt Microsoft ein klares Ziel: mehr Vertrauen in KI‑gestützte Rechercheergebnisse. Im Mittelpunkt steht dabei nicht, dass KI schneller antwortet, sondern dass ihre Ergebnisse besser geprüft, nachvollziehbar aufgebaut und verlässlich belegt sind.
Durch die konsequente Trennung einzelner Aufgaben übernehmen unterschiedliche KI‑Modelle klar definierte Rollen. Ein Modell erzeugt Inhalte, ein weiteres prüft diese kritisch anhand fester Bewertungsregeln, und bei Bedarf werden mehrere Modelle miteinander verglichen. Dieser Ansatz verhindert, dass eine einzige KI ihre eigenen Ergebnisse unkontrolliert bewertet.
Für die Anwender bedeutet das: KI‑Recherche wird transparenter, weil deutlich wird, wie Ergebnisse entstehen. Sie wird nachvollziehbarer, weil Aussagen strukturiert aufgebaut und sauber belegt sind. Und sie wird belastbarer, weil Schwächen, Lücken oder ungenaue Formulierungen gezielt erkannt und korrigiert werden.
Gerade für Unternehmen ist das entscheidend. KI‑Ergebnisse dienen immer häufiger als Grundlage für strategische, fachliche oder rechtliche Entscheidungen. Mit Critique und Council sorgt Microsoft dafür, dass diese Entscheidungen auf einer deutlich stabileren und vertrauenswürdigeren Informationsbasis beruhen.
Wie sieht die endgültige Antwort des Researcher-Agents aus?
- Visuals, Diagramme und Diagramme , um inhalte leichter verständlich zu machen.
- Organisierte Abschnitte , die Ihnen helfen, Ergebnisse klar darzustellen.
- Zitierte Quellen , damit Sie den Informationen vertrauen können.
Wo finden Sie den Mitarbeiter von Researcher?
Melden Sie sich beim App Microsoft 365 Copilot an. Sie finden Researcher unter Agents im Chat.
Wie verwenden Sie den Researcher-Agent?
Öffnen Sie Researcher in Microsoft 365 Copilot, stellen Sie Ihre Frage, und lassen Sie ihn Erkenntnisse aus vertrauenswürdigen Quellen sammeln. Erhalten Sie einen klaren Bericht mit wichtigen Ergebnissen und den nächsten Schritten, auf die Sie reagieren müssen.

Fazit
Mit Multi‑Model Intelligence entwickelt Microsoft den Researcher von einem einfachen Recherchetool zu einem professionellen Entscheidungswerkzeug weiter. Durch die Trennung von Erstellung, Prüfung und Vergleich steigt die Qualität von KI‑Recherche erheblich.
Critique und Council zeigen, wie KI im Unternehmensumfeld verlässlicher, transparenter und verantwortungsvoller eingesetzt werden kann – ein zentraler Schritt für den produktiven Einsatz von KI im Arbeitsalltag.
Kontaktieren Sie uns für mehr